

How I think about misinformation
An effort to write out the checks I use on everything I read

In the early 2000s, when I was a young teenager, there used to be emails going around saying weird scary things. One popular claim warned that gangs, as part of an initiation game, were killing anyone who flashed their headlights at them. Another warned against microwaving plastic containers, lest they release cancer-causing dioxins. These messages would often finish by imploring recipients to forward them to at least six people, or something might happen to you, or something.
These might seem silly enough to be funny now, but they were confusing at the time. I don’t have email archives from that era, but I’m sure I was responsible for passing on at least a few. By my mid-teens, my peers and I had figured it out and my inbox saw no more. But eventually they started arriving again — this time, from my parents. After years of getting terse replies with links to the first few Google hits, their forwards eventually shifted from “better safe than sorry” to, “is this true, Chuan-Zheng?”
Back then, it wasn’t called “misinformation”. That word’s prime has only really been in the last couple of years:

“Fake news” has been a bit more popular since around 2016:
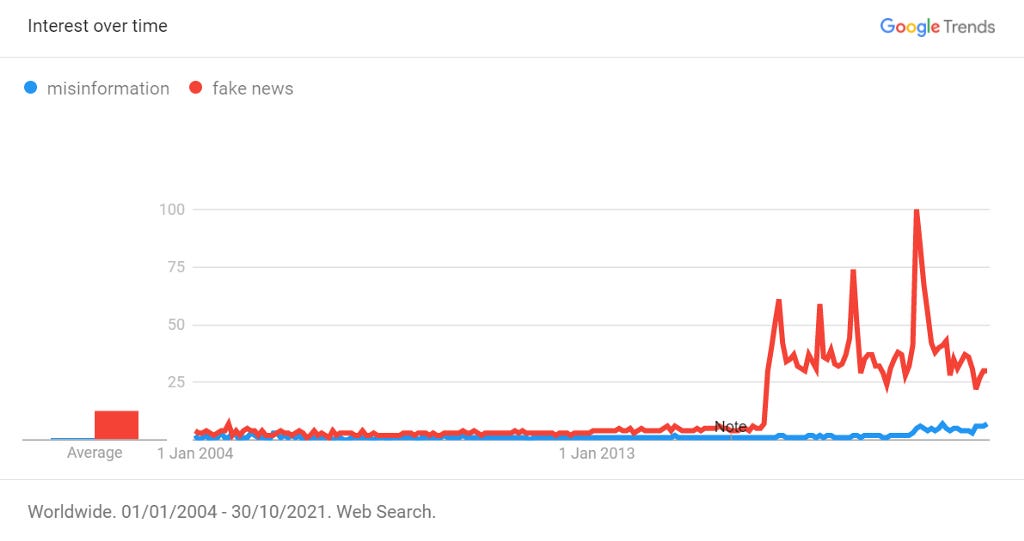
The Internet of today isn’t the Internet of the mid-aughts. But I feel like I had to learn the long, hard way to how to question everything I read. And I feel like that journey started very long before this became the hot topic of today.
This is an effort to write down what I’ve learnt. I try to catalogue what I actually do, not what I wish I did. I don’t know how many people already do these things. My feeling is that it’s not many, even among those who exhort others to, but I’m probably just smugly setting myself up for an ironic reality check.
Ready? Let’s get started.

Basic principles
Actually, there are two general principles I want to cover first.
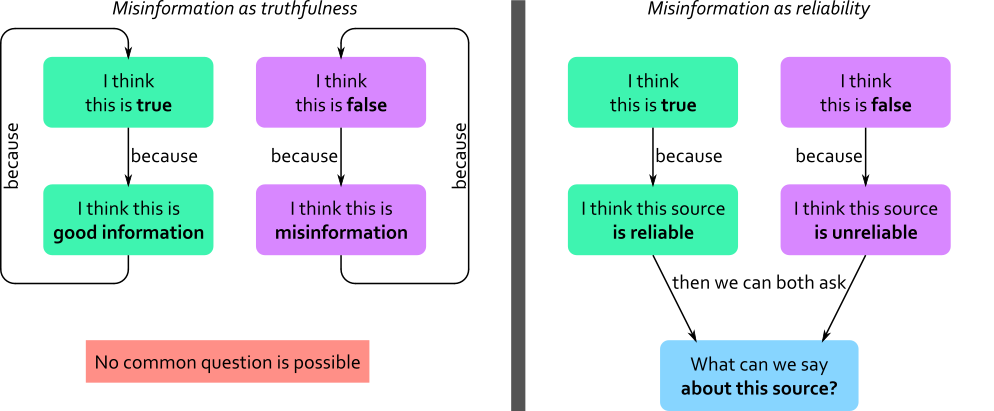
Principle A: I assess reliability, not truth
When I describe a claim as true, I mean what you think. The statement, “it is raining outside my house,” is true if rain is falling outside my house, and false if it’s not.
When I describe information as reliable, I’m assessing its source, not its content. Given where I found this information, how likely is it to be related to what’s true? If my flatmate is at home and tells me it’s raining there, that’s “reliable”. If my friend on the other side of the world says so, she might be correct, but she’s not as reliable as someone who’s physically there.
Neither “true” nor “reliable” imply the other. My flatmate might be wrong — maybe it started raining since he looked. My faraway friend might be right — maybe she checked the forecast for my city or made a lucky guess. But if all I have is their word, my flatmate is still more reliable than my overseas friend.
Such fine semantic distinctions demand a motivation, so let’s be more explicit. I think “unreliable” is a useful way to think about misinformation, and I think “false” is an unhelpful one.
This is partly philosophical. If misinformation means “false”, we have to know whether something is true or false before we can say whether it’s misinformation. But now we’re stuck in an infinite loop. The whole point of checking whether something is misinformation is to determine whether to believe it’s true. If, to understand whether we can trust information, we have to figure out whether it’s true, we’ve landed straight back on square one!

But it’s also pragmatic. If we label things “misinformation” because we know they’re false, then we lose any common ground with people whose prior beliefs are the opposite. This is sort of the information equivalent to “one man’s junk is another’s treasure”, except in this case it’s unhelpful. If everyone calls things “misinformation” if they think it’s false, and “good information” if they think it’s true, then there is no way to resolve an impasse by appeal to the concept of misinformation.
I’m in the minority here. Most dictionaries define “misinformation” using “incorrect”, “incorrect or misleading”, “false or inaccurate”, “wrong” or “wrong”, and about half include some sort of “intent to deceive”. Am I just redefining the word to suit my purposes? Guilty. The standard definition was probably helpful a decade ago, when it was used sparingly and “truth” was more universally sought, even if we didn’t always agree. But as the term’s gained currency, it’s been increasingly used to describe things opponents say that frustrate us. This is why I feel that defining misinformation in terms of truth leaves us in an impasse. I imagine having any of my beliefs labelled as “misinformation”, and I can’t imagine how that would make me want to reconsider rather than hurl the label straight back.
My proposition is that reliability offers something to assess that isn’t just a function of the claim. Annoyingly, reality isn’t tidy enough to permit a clean delineation between source and substance. But I think “where did this information come from?” offers at least some insulation from prior biases that “is this information true?” does not.
That said, if redefining a word doesn’t fly with you, I’ll stop saying “misinformation” from now, I’ll use “unreliable source” instead, and you can interpret all this as wanting to eschew “misinformation” as a concept.
(Eventually, we still have to figure out what to believe in the “truth” sense. I’ll circle back to this at the end, I promise.)
Principle B: I make a deliberate effort to check sources if I agree with what they say
In The Scout Mindset, Julia Galef writes that in what she calls “soldier mindset”, rather than asking, “is it true?”, we ask, “can I believe it?” or “must I believe it?” We’re naturally more rigorous with double-checking things we don’t want to believe, and more content accepting sources that confirm what we thought. Making a deliberate effort on things I agree with is an attempt to balance against this.
In case you think this is just for untrained minds — I think you see this a lot in academic research, including in world-leading institutions and journals. While all graphs in my doctoral thesis got at least a sanity check, there were a few that we treated with much more rigour, bordering on doubt. This wasn’t malicious, we weren’t trying to twist anything, it was all in earnest effort to find the truth — we were just more curious about the results that seemed odd. Academia is famously rife with time pressure. We all try really hard, but it’d be naïve to think that all findings get equal scrutiny in practice.
I don’t think I’m very good at this. I recently came across a video about that viral “6÷2(1+2)” question. Its conclusion matches my opinion, but it’s much more researched. Yet it’s still from a channel unfamiliar to me, and it makes a bold claim on a controversial topic. (See, e.g., this very popular video, which I want you to know is extremely wrong.) My first instinct was to take note of the (first) video’s sources, in case I ever need to “educate” someone. That attitude is troubling. I should’ve first thought to learn more about the video’s creator, and to double-check at least some of her claims — or at least open some of her links to references! I did so, but only after some reflection.
We naturally tend to be more lax with information we agree with. So I make a deliberate effort to compensate for it.
Things I do
Okay, here we are!
Quick heads-up: This list is long, and I don’t recommend trying to adopt this all in one go. Some of these habits involve developing skills, which takes time and practice. I’ve arranged these roughly from “easiest” to “hardest”.
1. If it’s shared in social media or messaging, without attribution detailed enough to find the author’s version, it’s not trustworthy.
In the 2000s, it was chain emails; nowadays, it’s infographics or copy-paste posts on Facebook or WhatsApp. These spread quickly: in April 2020, WhatsApp imposed limits on forwarding messages to combat misinformation. My rule with these is straightforward: If I can’t find the original, I ignore it.
This applies even if I trust the person sharing it. A regrettable reality I’ve learnt is that no one is immune from being hoodwinked by these forwards. Even if they’re really smart or really informed — I’ve seen both types fall victim to promoting unreliable sources that confirmed their instincts.
This applies even if the person sharing it is me.
If I’m sharing (hopefully good) information, I always share a link. If I include a screengrab, I still share a link. If the original is another tweet or post, I “quote tweet” or “include original post”. I consider this to be a basic courtesy: I include where it came from so that you don’t have to rummage around for it.
This applies even if the claims are within my expertise and I know them to be true. That’s not an excuse to share something that you, my audience, can’t verify. Either I write something original so that I’m your source (and you can discount accordingly), or I point you to the author using a link, quote-tweet or include-original-post.
(If lengthy URLs would cause undue clutter and I’m confident you can find it in a few seconds from a short description, I might just use that. This is normally only an issue on platforms that don’t support text hyperlinks.)
The other practices in this list are all fuzzy judgements I make as a reader. This one is the exception. The reading filter is part of it, but the sharing filter is just as important. I think that including links with everything we share should be considered basic etiquette in social media and messaging.
2. If I can’t find it on the first page of a Google search, it’s probably suspect.
This is a first-pass sanity check, and despite Principle A above, it’s not an assessment of the source itself. The idea is: things that are widely known are also easy to find. So if it’s not easy to find, then it’s not widely known, and if it’s not widely known, then it’s not reliable.
Google isn’t perfect, but it’s pretty good at finding relevant results quickly, so most things take just a few seconds to find. Nothing special about Google — I’m sure most major search engines will do great.
Some things take more digging. If I’m not done in a few seconds, I’ll normally take a few minutes trying different search terms, maybe a random sentence verbatim, to try to find the original. If this takes effort, it normally indicates some sort of controversy. Sometimes dissecting it is interesting, but most of the time, I’ll just take note that it’s controversial and move on.
Most things that go around the Internet are very googleable. This includes nonsense — they just turn up hits that explain how they’re nonsense. So in practice this only affects bold in-passing claims where someone can’t remember the source or the details.
3. If I can’t find many sources saying the same thing, I take it with a grain of salt.
This is the next step after (2). I don’t just look at the first search hit or highlight and call it a day — I skim the first few extracts to check that they all say similar things.
I check multiple sources even if the first source I have is reputable. Even the most reputable publishers are occasionally fallible, and having different agencies run independent checks is part of the overall check. Did you see this article in early September 2021?

Scott Alexander has the whole journalistic saga written out, but basically, one hospital distanced itself from the comments, the doctor later said he was misquoted, and The Guardian later softened its headline. Sadly, many news outlets reported similarly, so this wouldn’t have been caught by this test — but hopefully it’s an existence proof for “even reputable outlets aren’t perfect”.
Things that can complicate this:
If the article’s not about the newspaper’s home, I look for reporting on a local news site. This can be challenging, as local articles often omit context that locals can be assumed to know, but I find that foreign papers often unduly dramatise things.
An authority’s website is normally authoritative about itself. Examples: official legislation sites, tax departments, sports rules on governing body sites. Though, human error can creep in, and some authorities are better at keeping websites up to date than others.
However, government advice on things like science (e.g. CDC on COVID) and history should be corroborated, like everything else.
Some new scientific results get widely reported; others don’t. In either case, I treat new results as “unreliable” in a sense: no single academic work is by itself conclusive. The nature of scientific studies is that they have to be narrow to be tractable, so each study offers only a hint to the big picture.
To give you some idea of how seriously I take this: If I’m looking up a word, unless I’m already 90% sure, I look in at least two dictionaries, sometimes as many as four. I’ve set up shortcuts in my browser to make this easier. Did you notice how many links I had above for the definition of “misinformation”? Or on WhatsApp forwarding limits?
4. If I’m not familiar with the website, I check its “about” page.
Almost all websites have one. If it doesn’t, it’s a major red flag.
On platforms like Facebook or YouTube, this means their profile or channel page. Many have links to other platforms or their website; this helps. Personal channels can be reliable (and valuable) — they’ll normally have a paragraph or so somewhere describing their background and what they’re hoping to achieve with their channel/page. Not disclosing their full name gets only a minor discount — their background, context, objective and track record are much more important.
I check even if they have an authenticity tick. Those ticks guarantee identity (they are who they say they are), not reliability (of what they say).
I check even if they have an authoritative-sounding name. This isn’t because they might be misleading — it’s just context. The New Zealand Educational Institute is a trade union, not a research institute. The Council on Foreign Relations is a think tank, not a government body. This doesn’t make them unreliable or bad — it’s just useful to know where they’re coming from.
If I’m looking at a PDF file, Google Doc or similar, I expect the document to show the organisation and/or author responsible for it. I should also be able to find it on the organisation’s website — this is how I check it isn’t fabricated.
Basically, if someone writes or creates something interesting, I want to learn a bit more about them! If it’s an organisation, I want to learn about them too! This is a reliability check, but it’s also very cool learning about all the people in the world trying to make a difference.
(If you don’t know me personally — have you checked my “about” page? Tried to figure out who I am in any other way?)
5. If it relies heavily on a quoted expert who I don’t already know about, I check their public profile.
First: Do they exist, and are their affiliations and expertise actually as quoted? If they’re an academic, virtually all academics (including PhD students) have an academic page — can I find it?
I find that first check is easy about 90% of the time. Either I can’t find evidence of their existence, or I can find a track record of work in the area. But sometimes I have to dive into the weeds.
I debated with myself over how much to elaborate on this. The other 10% of the time gets really tricky, really quickly. Assessing expertise relies on knowing about domains and institutions of knowledge. Maybe you know biology from physics, but do you know polymer chemistry from synthetic chemistry? You’ve probably heard of MIT and Cambridge, but did you know that Switzerland has two world-class technical universities?
I think this is highly non-obvious and too easily weaponised. You know those “my expert is better than your expert” wars that descend quickly into ad hominem attacks? If your first reaction to that was, “omg I know, those scumbags do that all the time” — you probably do this too. It’s very difficult to fight confirmation bias on this one. But if we reject expertise because of what they claim, we’re in the same circular dependency I warned about in Principle A.
So this is like an “intermediate” skill 90% of the time, and a hot mess 10% of the time. And… I could offer heuristics, but honestly, that 10% doesn’t matter that much. Once I’m splitting hairs about their credentials, I may as well just file the whole thing under “controversial”.
(By the way, did you verify my claim about Swiss technical universities? ¹ ²)
6. I read what the text literally says, and no more.
It’s common to lament that articles are misleading, but I actually find that most writers, especially most journalists, are careful with their words.
If someone (X) said something (Y), but they can’t verify Y, they don’t say “Y”, they say that “X said Y”. If they want to pad the article with tangentially relevant facts, they just give the tangential facts; they don’t attempt to explain their (ir)relevance.
It’s annoying, sometimes infuriating, when an article portrays things in an undeserved light. My defence is not to read into the text any more than what the text actually says. I can’t stop everyone else drawing undue conclusions, but I can stop myself.
Sometimes this makes a huge difference. Remember that ivermectin article from The Guardian I mentioned earlier? Here was the BBC:
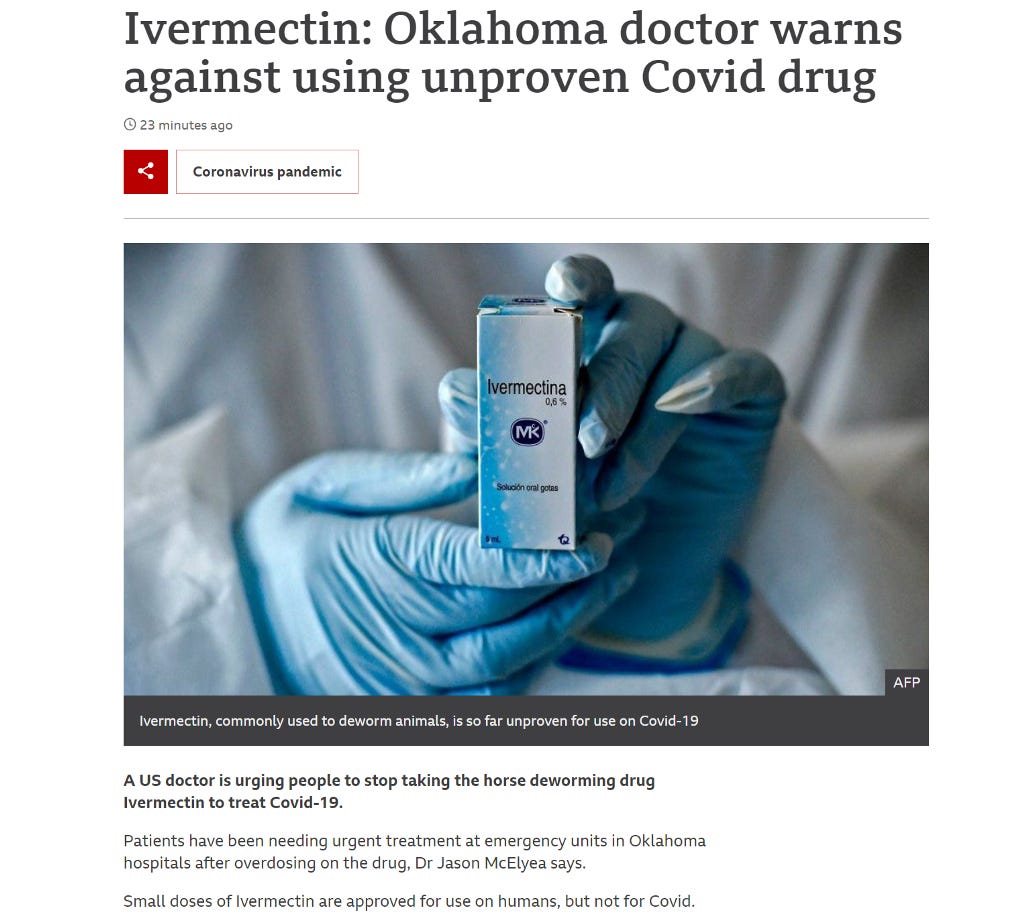
A careful read of this article is not nearly as exaggerated as the Rolling Stone version (“Gunshot Victims Left Waiting as Horse Dewormer Overdoses Overwhelm Oklahoma Hospitals, Doctor Says”), which is (of course) the one that went viral. The BBC doesn’t claim that ivermectin cases are causing overcrowding — just that some are showing up to already-stretched hospitals.
Here’s another example, possibly more surprising. This provocative article was third on the Fox News home page when I wrote this paragraph:
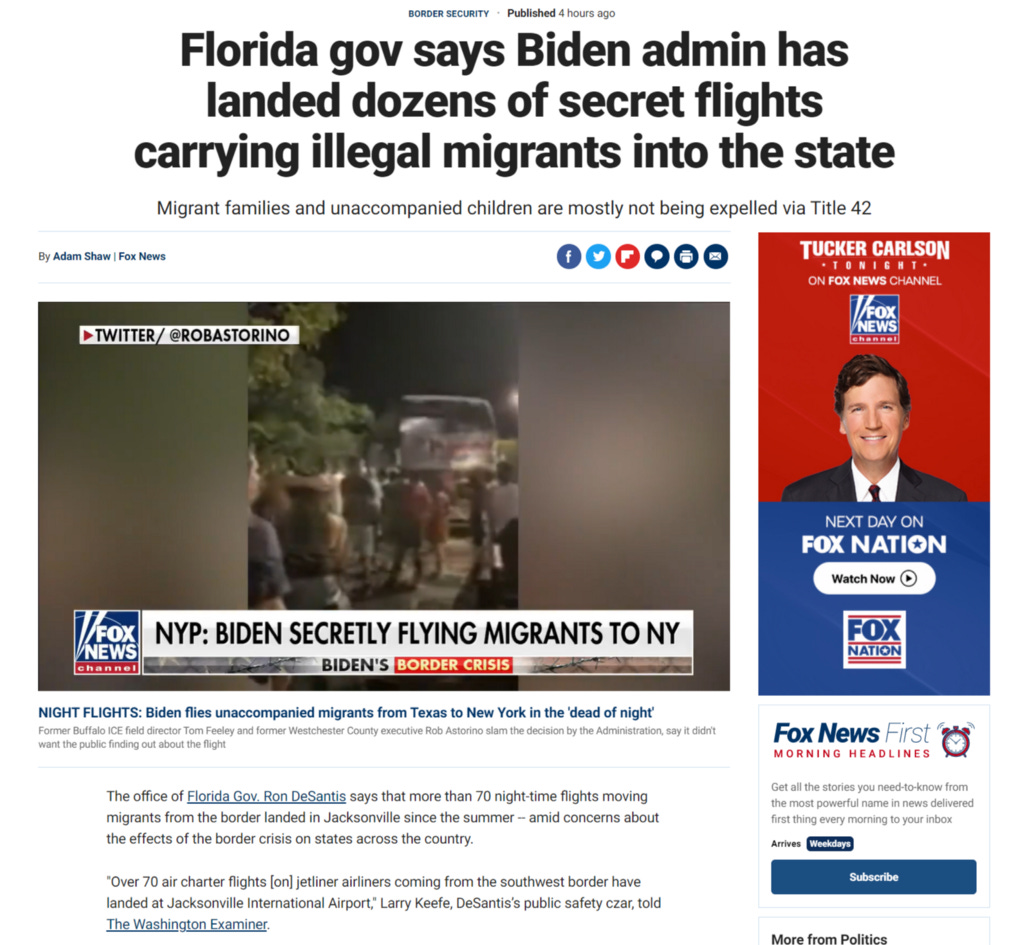
Your first reaction might be to the “secret flights” part. But the article doesn’t allege that such flights are happening — it merely says that “the office of Ron DeSantis says” so. And it’s not Fox’s original reporting — they point to the Washington Examiner, which is similarly deferential. There aren’t any “facts” to debunk here. The article merely recounts the claims of a political office. You might wonder why this is newsworthy (I do too), but the article itself is probably not lying.
7. I try to understand the target audience of the resource.
If you’ve even been taught how to write, you’ve probably heard something like “know your target audience”. You’d talk and write differently depending on whether it’s to your friends, colleagues, clients or the general public. I think we should understand this as readers, too. Even if you’re reading it, the target is not necessarily you — lots of documents are publicly accessible, because it’s less hassle. But to better understand what they mean, I find it helps to ask before I start reading: Who are they writing this for?
Examples:
All newspapers have a slant. Some (e.g. Reuters) are strictly facts, no analysis. Some (e.g. The Economist) are very into analysis. Most have biases and write for an audience that wants that bias. A few are going for clicks. There’s nothing bad about any of this — it’s good to have a diverse media landscape — it’s just something to keep in mind.
Academic papers are written for other researchers in their discipline. They often try to persuade readers (ahem, reviewers) that they’re making a novel contribution. But their peers also know that each paper is but a small piece towards an intimidatingly large picture. I find that advocates and “science journalists” often forget this, and relay findings with more zeal than warranted.
Some records sacrifice accuracy for completeness: they’d rather have everything plus lots of noise, than miss something. Topical example: vaccine reaction reporting systems.
Many documents aimed within a community (e.g. a sports league, a political movement, a company, a discipline, a blogosphere) assume prior knowledge and possibly prior biases that people outside that community may not be familiar with.
If you’re not the target audience, this doesn’t mean you can’t read it! I just try and read it with that target audience in mind, to avoid misinterpreting what they mean.
Important caveat: This is the hardest of the practices on this list. There’s a lot of knowledge involved: which newspapers lean which ways, how various worlds (academic, political, legal…) operate, what political worldviews exist. I don’t have a shortcut for this. The best I can say is that it’s lifelong learning: I think I’ve made some progress, I still have a long way to go, and I don’t think anyone should feel a need to master this before they can assess information, otherwise you’d never start. But where I can say something about the target audience, I find it helps temper any immediate reactions I might have.
If you’ve made it this far, firstly, congratulations and thanks for staying with me! And secondly, you might have noticed a problem. I’ve listed a lot of filters for what not to believe. But then, what do I believe? With all these rules, doesn’t it seem like I’ll never believe anything?
Well, that’s kind of true. The answer lies in that question I promised I’d return to all the way back in Principle A, when I distinguished between “true” and “reliable” and suggested that the latter is more useful. How do I get from the information I see, to what I think is true?
Thinking in degrees of confidence
You can think of this as my Principle C, if you like: I try not to think of statements as having a binary state of “true” or “false”. Instead, I use a confidence spectrum:
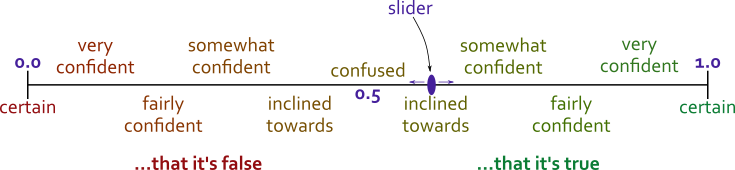
I think about facts as having some confidence level that slides along this scale. The scale runs from 0 to 1. Closer to 0 means more confident it’s false, and closer to 1 means more confident it’s true. If I see information that supports a claim, the slider moves closer to 1. If I see information that contradicts it, it moves closer to 0.
(Technically these are credence levels, and “confidence” means something different, but I often say “confidence” because I think it makes more sense.)
People call this “Bayesian thinking”, after Bayes’ theorem, which describes the mathematical formula to update credence levels. I first encountered it in Nate Silver’s 2012 book The Signal and the Noise. Here are some good videos on it: Julia Galef (more about how to think), Matt Parker & Hannah Fry (more fun, about the history), Grant Sanderson (to understand the theorem).
But before you run away from the maths, wait! There’s no need to run exact calculations. The point is the principle: I maintain a confidence level for each belief, and it moves, or “updates”, in response to new evidence.
For me, how far I move the slider depends on a few things, including:
how reliable the source is,
how direct the evidence is (e.g. whether it’s measuring a proxy),
how strong the evidence is (e.g. effect size, statistical significance),
the biases of the commentator (update more if they’re saying something “against their side”).
In The Scout Mindset, Julia Galef posits that this system makes it less emotionally taxing to change your mind. We treat changing our minds like a really big deal — and it kind of is, if you go straight from “it’s true” to “it’s false”. No wonder we’re so resistant to it! But if you update incrementally, stepping from “fairly confident” to “somewhat confident” with one piece of new information, then to “inclined towards” with the next, each step is smaller and feels less momentous.
But let’s return to the question I left open. How does this help me get from “information I mostly rule out” to “believing things”? Well, most individual pieces of evidence don’t sway me very much, but if I have lots of sources pointing in the same direction, together they can offer a lot of confidence. Imagine that each source moves the slider in the same direction — eventually I end up in “fairly confident” territory. If different sources pull in different directions, I might end up in “confused”, and that’s fine. I find with most things, I land somewhere good enough for practical purposes.
Bayesian updating: An example
Do the COVID vaccines appreciably reduce transmission? Don’t take the numbers or timeline too seriously, I’m plucking them out of the air/my memory, but hopefully this demonstrates the idea of Bayesian updating:
When the vaccine first became available to priority groups, there weren’t any studies specifically on transmission. I started at around 0.65, since I’d probably expect it to follow from reducing infection.
The first studies I heard of were indirect (measuring viral load rather than transmission). Public officials continued to equivocate. Up to 0.7.
Breakthrough infections became frequent. This isn’t inconsistent with reducing transmission, but it rules out preventing transmission, which still pushed down my credence on reduction a little, back to 0.65.
I never perused studies myself, but after a month, all the commentators I trust seemed pretty happy with the evidence. Up to 0.8.
Recent new variants complicate this again. Probably around 0.75.
(I should say that I’ll personally probably never go past 0.1 or 0.9 on this, because I don’t care enough to investigate thoroughly.)
Final thoughts
I guess that’s a lot. It must seem ridiculously onerous to go through all those checks with everything I see. The truth is, I don’t. Most things aren’t noteworthy enough to care much for. But also, I got faster at this the more I did it. With practice, I got better picking good search terms, skimming for relevant details, focusing on the parts most likely to be tenuous.
But if I’m getting faster, how do I know I’m also not becoming less thorough? If I’m skipping nonpivotal checks, how do I check my “especially deliberate effort to check sources if I agree with what they say” from Principle B?
I don’t really have a good answer to this. I try my best, probably fail often, and hopefully at least notice some of the time so I can correct myself. I guess the best I can say is not to expect immediate perfection at this.
After all, what I’ve laid out here is just a part of what I’ve so far spent nearly two decades figuring out. Give me another decade and I’m sure half of it will have changed again. I don’t want you to take this as some sort of authoritative guide to misinformation — if you were going to, my writing has failed! But if these ideas interest you at all, my suggestion is to start small.
A first step is developing the reflex, “wait, is that right?” whenever you react to something. That doesn’t come naturally. Then, focus on one habit at a time. It probably doesn’t matter which. I started by typing things into Google, then slowly got better at choosing search terms and picked up on Bayesian thinking. Then, even more slowly, I kept learning more about different websites, institutions of knowledge and the world. That journey continues today, and will probably never end.